网格和任务(放大)着色器是对现有着色器集的一个很好的补充。它们允许使用自定义数据格式来实现更好的压缩,并且可以动态生成几何图形,而无需使用中间存储。让我们看看它们在不同硬件和 API 上的表现如何。
我们将为此使用两个简单的测试应用程序。无需任务着色器乘法即可绘制一百万个独立的四元图元。Nvidia 可以调度一百万个任务着色器调用,但这样的数字会使 AMD 驱动程序崩溃。为此,我们将使用 16 个任务着色器批次。每个网格着色器的几何输出仅为 4 个顶点和 6 个索引。
第二个应用程序绘制许多复杂的模型实例。每个模型由 283K 个顶点和 491K 个三角形组成。实例数量为 81。这需要处理 20M 个顶点和 40M 个三角形。Meshlet 的数量取决于顶点/图元数量,从 6130 到 2709 不等。顶点缓冲区的大小也在增加,因为每个 Meshlet 必须是独立的。没有几何剔除。我们仅检查几何吞吐量。
两个应用程序都可以使用单个 MultiDrawIndirect 命令单独绘制所有 Meshlet。不使用实例化。
| D3D12 MS | D3D12 MDI | D3D12 VS | VK MS | VK MDI | VK VS | |
|---|---|---|---|---|---|---|
| GeForce 2080 Ti 4/2 | 685米 | 707米 | 655米 | 360米 | ||
| GeForce 2080 Ti 64/84 | 12.92乙 | 11.20乙 | 11.34 乙 | 10.80 乙 | ||
| GeForce 2080 Ti 64/126 | 12.51乙 | 11.21乙 | 11.71乙 | 10.92乙 | ||
| GeForce 2080 Ti 96/169 | 12.71乙 | 11.23乙 | 11.27 乙 | 11.44 乙 | ||
| GeForce 2080 Ti 128/212 | 12.12乙 | 12.20乙 | 10.84乙 | 11.72乙 | ||
| GeForce 2080 Ti 32 位索引 | 11.79 乙 | 10.95乙 | ||||
| Quadro RTX 8000 4/2 | 683米 | 693米 | 661米 | 345米 | ||
| Quadro RTX 8000 64/84 | 12.51乙 | 15.26 乙 | 14.72乙 | 12.31 乙 | ||
| Quadro RTX 8000 64/126 | 12.23乙 | 15.37 乙 | 14.30乙 | 12.83乙 | ||
| Quadro RTX 8000 96/169 | 12.50 乙 | 16.62乙 | 14.05 乙 | 15.39 乙 | ||
| Quadro RTX 8000 128/212 | 12.15 乙 | 17.04 乙 | 13.43乙 | 15.64乙 | ||
| Quadro RTX 8000 32 位索引 | 13.63乙 | 12.88乙 | ||||
| Radeon 6700 XT 4/2 | 118M | 85.1M | 85.5M | |||
| Radeon 6700 XT 64/84 | 4.31乙 | 3.42乙 | 3.40乙 | |||
| Radeon 6700 XT 64/126 | 4.37乙 | 3.61乙 | 3.59乙 | |||
| Radeon 6700 XT 96/169 | 4.43乙 | 5.48乙 | 5.40乙 | |||
| Radeon 6700 XT 128/212 | 4.49乙 | 7.42乙 | 7.31乙 | |||
| Radeon 6700 XT 32 位索引 | 14.68乙 | 14.16乙 |
该表显示了每秒渲染的三角形数量。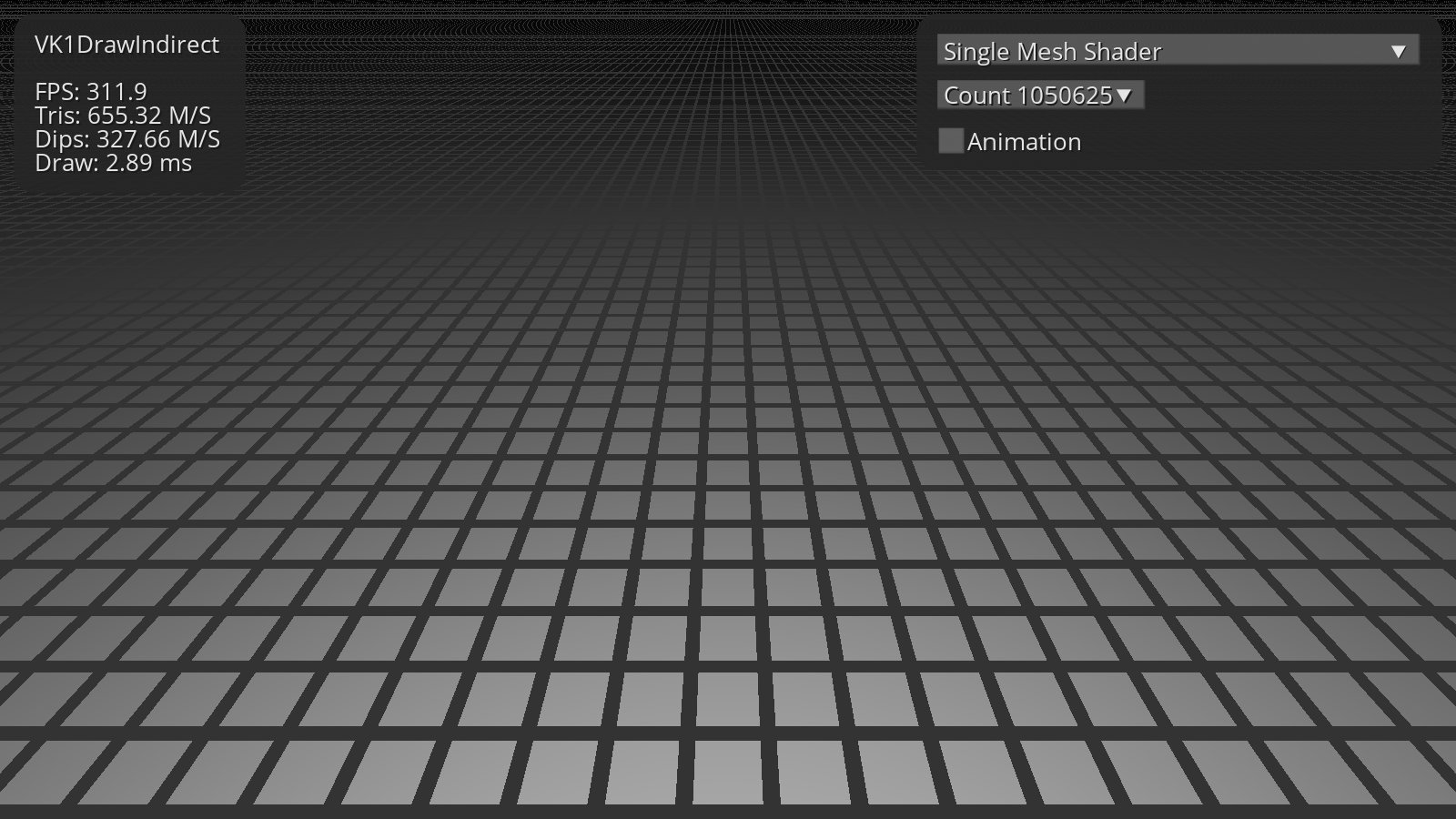

结果非常有趣:
- MultiDrawIndirect 比 Nvidia Quadro 上的网格着色器更快。
- 对于 Nvidia 来说,Mesh 着色器和 MultiDrawIndirect 之间没有区别,除了 Vulkan 的图元数量非常少。
- 原始几何图形的 32 位索引在 AMD 上运行速度更快。但任何网格着色器配置都会使硬件功能降低 3 倍。更重要的是,当图元数量大于 128 时,MultiDrawIndirect 方法开始比网格着色器工作得更快。
但让我们尝试使用几何着色器来绘制 256K 的盒子。我们将使用另一个简单的应用程序来绘制 3D 盒子网格。每个盒子都是几何着色器的一个点基元。网格着色器将为每个任务着色器组绘制 64 个框。
| D3D12 MS | D3D12 GS | VK MS | VK GS | |
|---|---|---|---|---|
| GeForce 2080 钛 | 1.5乙 | 3.7乙 | 1.5乙 | 2.9乙 |
| Radeon 6700 XT | 1.4乙 | 2.2乙 | 1.9乙 |
几何着色器在这里显然是赢家,尤其是在 Nvidia 硬件上。
正确实现的 MultiDrawIndirectCount 允许完成与网格着色器相同的工作。几何着色器比网格着色器能更好地完成简单的图元渲染。我们希望供应商能够提供更好的 API 灵活性,而不是实现大量不同的着色器类型。
以下是来自网格着色器的更多观察结果:
- 即使着色器组大小大于 32,所有网格着色器顶点和索引也必须由 Nvidia 和 Vulkan 上低于 32 的线程写入。否则,结果将被忽略。
- Nvidia 可以在 D3D12 和 Vulkan 下调度任意数量的任务着色器组。AMD 的限制为 65K。
Clay 着色器编译器可以自动将任务和网格着色器从 GLSL/SPIR-V 转换为 HLSL。
Windows 复制二进制文件:TellusimDrawMeshlet.zip