Apple Metal API 最重要的遗漏是缺少 MultiDrawIndirect 功能。MDI 是 GPU 驱动技术最兼容的渲染方式。我们可以通过多种方式在 macOS 和 iOS 上模拟 MDI。
最简单的方法是循环使用不同间接缓冲区偏移量的drawIndexedPrimitives()命令。MultiDrawIndirectCount 将需要 CPU-GPU 同步才能从 GPU 内存获取计数值。也许这不是一个非常理想的方法,但它确实有效,并且由于驱动程序优化不足,甚至可以在某些硬件上胜过单个 MDI 调用。for(uint32_t i = 0; i < num_draws; i++) { [encoder drawIndexedPrimitives:… indirectBufferOffset:offset]; offset += stride; }
Metal 官方的方式是使用 Indirect Command Buffer,在 CPU 或 GPU 上编码渲染命令。所有纹理和样本都必须作为参数缓冲区参数传递,即使它们在渲染过程中没有发生变化。Metal 着色语言有一个内置的draw_indexed_primitives()函数,它100%对应于它们的Metal API模拟。听起来不错,除了 16384 个绘图命令的小限制之外。
理论上,对executeCommandsInBuffer() 的单次调用必须轻松优于drawIndexedPrimitives() 循环。但让我们对此进行一些测试。我们将使用在网格着色器性能比较中使用的相同应用程序。
| 环形 | 国际商业银行 | VS | |
|---|---|---|---|
| 苹果M1 4/2 | 20M | 48米 | |
| 苹果M1 64/84 | 698米 | 794米 | |
| 苹果M1 64/126 | 740米 | 840M | |
| 苹果M1 96/169 | 1.22乙 | 933米 | |
| 苹果M1 128/212 | 1.49乙 | 1.05乙 | |
| Apple M1 32 位索引 | 1.36乙 | ||
| Radeon Vega 56 4/2 | 24米 | 16米 | |
| Radeon Vega 56 64/84 | 1.13乙 | 647米 | |
| Radeon Vega 56 64/126 | 1.20乙 | 687米 | |
| Radeon Vega 56 96/169 | 1.84乙 | 1.05乙 | |
| Radeon Vega 56 128/212 | 2.54乙 | 1.44乙 | |
| Radeon Vega 56 32 位索引 | 3.9乙 |
- 当 Apple GPU 上每次绘制调用的基元数量较小时,ICB 的性能优于循环。但当 DIP 包含超过 200 个原语时,ICB 会慢 1.5 倍。而这就是ICB的一种奇怪行为。
- ICB 总是比 AMD GPU 上的间接命令循环慢近两倍。但令人兴奋的是,耗电的 AMD Radeon Vega 56 的运行性能与集成的 Apple M1 大致相同。
但是在 Direct3D12 和 Vulkan 下使用相同的硬件运行测试怎么样:
| 金属环 | 金属ICB | D3D12 MDI | VK MDI | |
|---|---|---|---|---|
| Radeon Vega 56 4/2 | 24米 | 16米 | 34米 | 34米 |
| Radeon Vega 56 64/84 | 1.13乙 | 647米 | 1.34乙 | 1.33乙 |
| Radeon Vega 56 64/126 | 1.20乙 | 687米 | 1.41乙 | 1.40乙 |
| Radeon Vega 56 96/169 | 1.84乙 | 1.05乙 | 2.13乙 | 2.11乙 |
| Radeon Vega 56 128/212 | 2.54乙 | 1.44乙 | 2.91乙 | 2.84乙 |
- 间接命令的循环几乎与单个 API MDI 调用一样快。但性能的代价是巨大的CPU负载。ICB 和 MDI 解决方案根本不加载 CPU。
- 所有 AMD GPU 都具有原生 MDI 功能,甚至适用于 D3D11,但不适用于 Metal。AMD GPU并不是苹果的主要目标,这是可以理解的。
GravityMark 基准测试的当前版本使用循环方法来渲染 Metal。这极大地降低了相同 AMD GPU 的性能:
ICB 不是一个广泛使用的功能,而且很难调试。金属着色器验证仍然与 ICB 不兼容。应用程序崩溃:-[MTLGPUDebugDevice newIndirectCommandBufferWithDescriptor:maxCommandCount:options:]:1036: 断言失败“着色器验证当前不支持间接命令缓冲区”
幸运的是,有 MTL_SHADER_VALIDATION_GPUOPT_ENABLE_INDIRECT_COMMAND_BUFFERS 参数可以启用 ICB 验证。但平凡的 ICB 着色器可能会导致不平凡的错误:编译器遇到内部错误
可以简化一个简单的 ICB 着色器,使其能够通过编译阶段。然后MTLArgumentBuffer会提醒他也有自己的调试器:
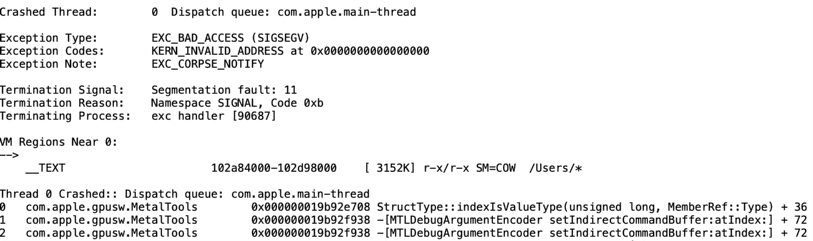
好的,现在 ICB 无法调试。让我们尝试一下没有它。好消息是,发生错误时 macOS 通常不会挂起超过 20 秒。更常见的是,漂亮的洋红色屏幕表明出现了问题:

因此,我们拥有了 GravityMark 的内部 ICB 版本,它表明:
- 需要 GPU-CPU 同步,因为executeCommandsInBuffer() 的间接版本会导致 M1 上出现洋红色屏幕。
- 16384 ICB 长度限制对于所有小行星来说都太低,因此我们应该重复executeCommandsInBuffer() 命令的间接版本几次。
- AMD 使用ICB比使用Loop慢 18% 。唯一的好处是CPU是免费的。Mac 上的本机 Windows 或 Linux 将使图形性能提升 3 倍。
- M1 使用ICB比使用Loop快 39% 。如果没有同步的话应该会更好。但即使有此限制,M1 的性能仍优于最好的集成 GPU。
- A14 使用 ICB 比使用 Loop 快 44%。它在最后一次拍摄时崩溃了,得分结果是 3600 而不是2536。
- 现在不是购买配备适用于 macOS 的 AMD GPU 的 Mac 的好时机。