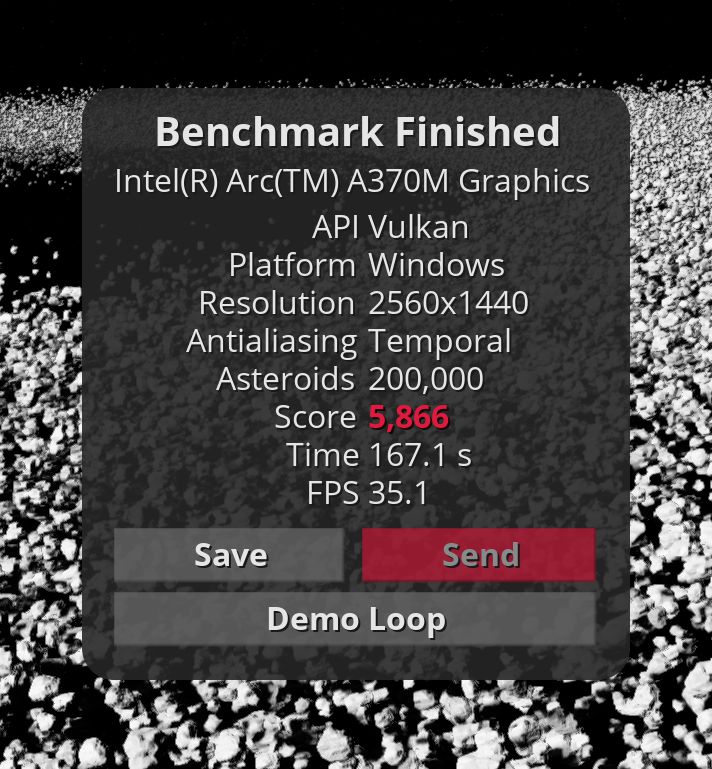
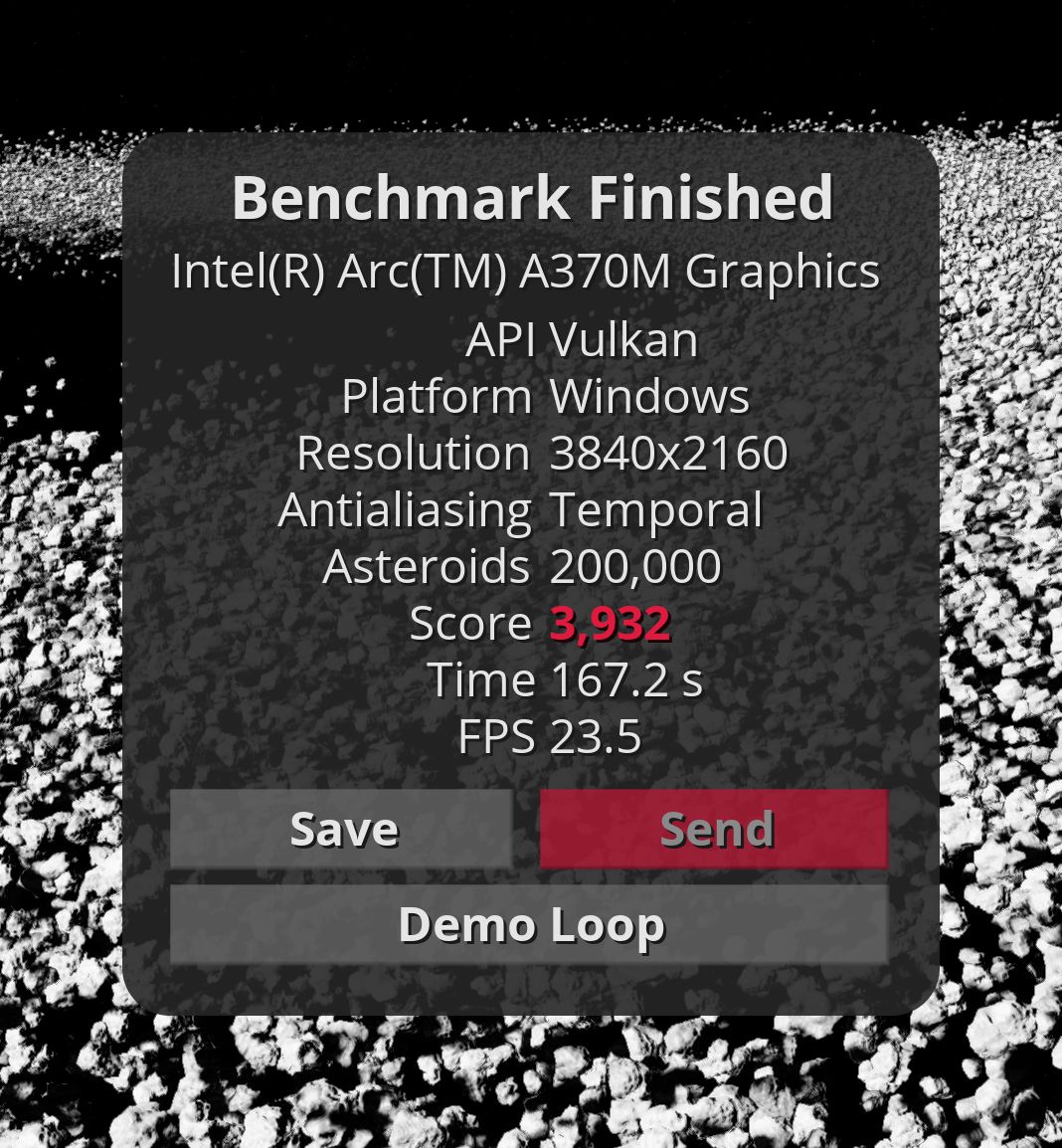
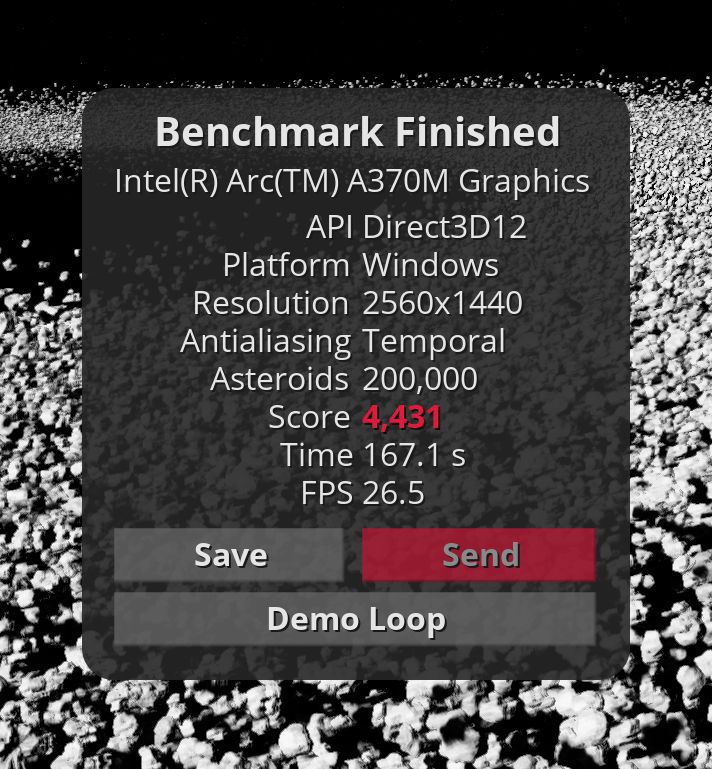
Intel Arc GPU 不久前就已经发布了,但直到现在我们才有机会分析它的性能。由于 VK 在 Intel GPU 上的性能较低,我们将使用 D3D12 API 进行测试。Arc GPU 的驱动程序版本为 30.0.101.1736,而 Xe GPU 的驱动程序版本为 30.0.101.3109。主要关注点是与其他 GPU 相比的原始 Arc GPU 性能。我们可以轻松地推断这些数字,以获得即将推出的 Intel Arc 770M 的大致性能,该处理器具有 4 个内核和更快的内存。所以只需将结果乘以(除)4即可。
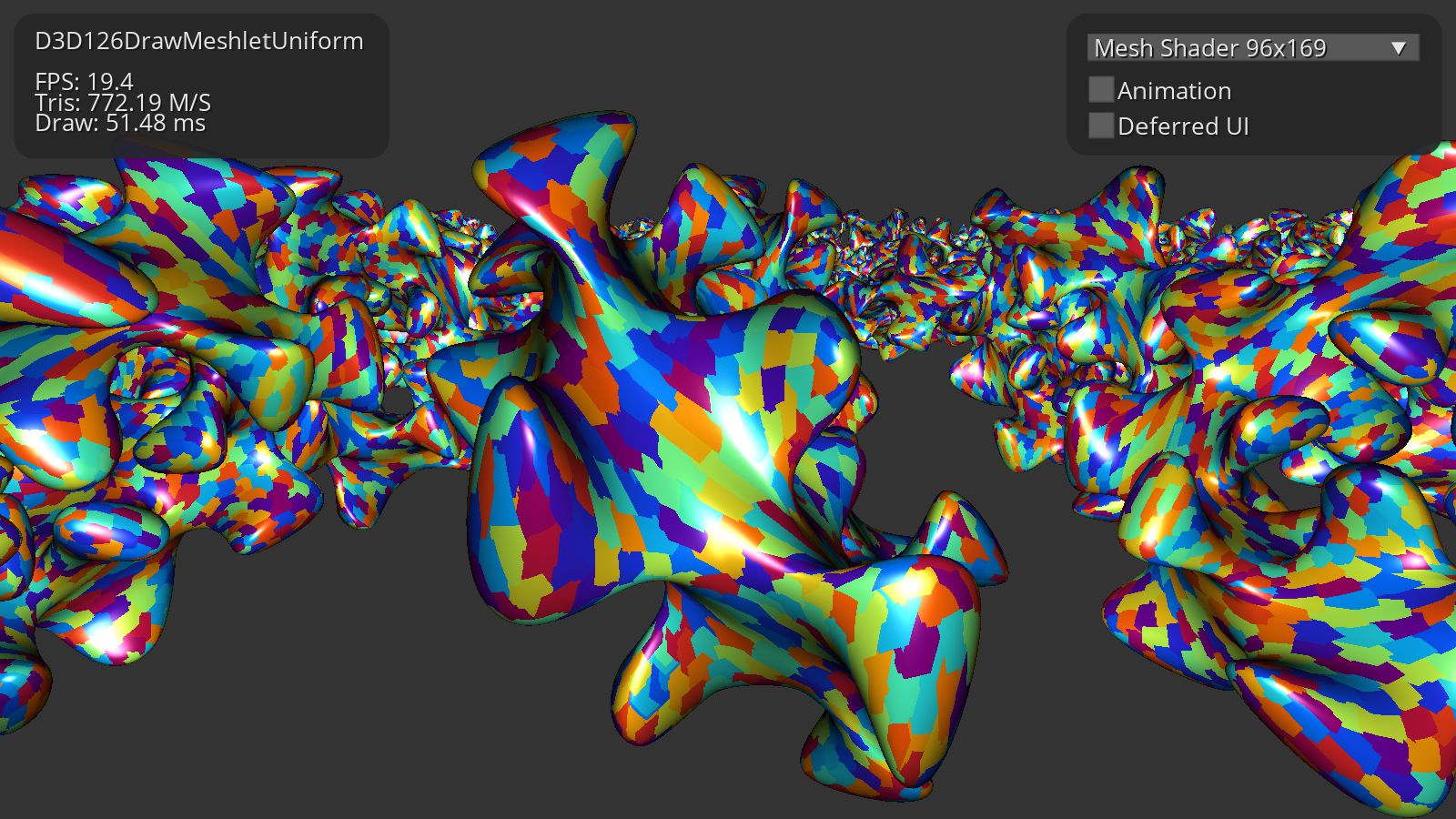
我们将在第一次测试中看到新 GPU 如何处理三角形和批次。这与我们之前使用的测试相同。Meshlet 尺寸为 69/169。测试渲染 262K Meshlet。每帧几何体总量为 20M 个顶点和 40M 个三角形。
| 单拨码 | 网格索引 | MDI/ICB | 网格着色器 | 计算着色器 | |
|---|---|---|---|---|---|
| 英特尔Arc A370M | 3.2B | 1.0B | 2.9B | 770M | 3.0B |
| 英特尔 Iris Xe(第 12 名) | 1.6B | 450M | 1.6B | 2.9B | |
| 英特尔 Iris Xe(第 11 位) | 1.2B | 370M | 400B | 2.3B | |
| 苹果M1 Max | 8.3B | 3.5B | 2.2B | 12.3B | |
| 苹果M1 | 1.4B | 648M | 1.0B | 2.7B | |
| GeForce 2080 钛 | 15.5B | 5.2B | 17.5B | 14.3B | 17.8B |
| 英伟达精视1060 | 3.8B | 1.2B | 4.0B | 4.5B | |
| Radeon 6700 XT | 14.2B | 6.2B | 6.3B | 4.6B | 17.0B |
| Radeon 5600 M | 5.0B | 2.4B | 2.1B | 7.4B | |
| Radeon 4800H | 1.2B | 530M | 1.2B | 1.5B | |
| 肾上腺素730 | 890M | 287M | 120M | 423M |
- 单位是每秒十亿或百万个三角形。
- 单个 DIP正在使用 u32 索引绘制 81 个实例,而无需进入 Meshlet 级别。
- 网格索引是这篇文章中的网格着色器模拟技巧。
- MDI/ICB是多绘制间接或间接命令缓冲区。
- Mesh Shader使用的是 Mesh Shaders 渲染模式。
- 计算着色器正在使用计算着色器光栅化。
Intel Arc 370M 在三角形光栅化吞吐量方面提供了 2 倍的性能提升。但遗憾的是,Compute Shader 计算量并没有增加,Arc GPU 表现出与 Xe GPU 几乎相同的结果。与使用 DDR4 的第 11 代相比,第 12 代 Xe GPU 还受益于增加的 DDR5 内存带宽。新一代 Xe 的 MDI 性能也大幅提升 4 倍。
Mesh Shader渲染性能不好。GPU 损失了理论三角形吞吐量的 4 倍。网格着色器模拟技巧也比 Intel Arc 上的网格着色器更好。

第二个测试是使用 CS 和 API (HW) 渲染模式的光线追踪测试。
| 静态CS | API静态 | CS动态快速 | API动态快速 | CS动态完整版 | API动态完整 | |
|---|---|---|---|---|---|---|
| 英特尔Arc A370M | 15.0 帧/秒 | 142帧/秒 | 23.8 帧/秒(8 毫秒/15 毫秒) | 62.3 帧/秒(8 毫秒/3 毫秒) | 12.0 帧/秒(53 毫秒/12 毫秒) | 20.8 帧/秒(40 毫秒/3 毫秒) |
| 英特尔 Iris Xe(第 12 名) | 11.5 帧/秒 | 12.5 帧/秒(14 毫秒/56 毫秒) | 7.4 帧/秒(76 毫秒/32 毫秒) | |||
| 英特尔 Iris Xe(第 11 位) | 10.1 帧/秒 | 8.8 帧/秒(17 毫秒/60 毫秒) | 5.4 帧/秒(101 毫秒/50 毫秒) | |||
| 苹果M1 Max | 68.4 帧/秒 | 63.9 帧/秒 | 34.8 帧/秒 | 28.7 帧/秒 | 28.5 帧/秒 | 2.7 帧率 |
| 苹果M1 | 16.5 帧/秒 | 16.5 帧/秒 | 11.3 帧率 | 14.3 帧率 | 7.3 帧率 | 1.7 帧率 |
| GeForce 2080 钛 | 74.2 帧/秒 | 803帧/秒 | 74.5 帧/秒(2 毫秒/8 毫秒) | 353 帧/秒(1.1 毫秒/0.6 毫秒) | 58.1 帧/秒(8.8 毫秒/5 毫秒) | 61.2 帧/秒(15 毫秒/0.5 毫秒) |
| 英伟达精视1060 | 18.0 帧/秒 | 16.8 帧/秒(10 毫秒/35 毫秒) | 13.7 帧/秒(32 毫秒/26 毫秒) | |||
| Radeon 6700 XT | 134帧/秒 | 368帧/秒 | 62.7 帧/秒(3 毫秒/10 毫秒) | 155 帧/秒(5 毫秒/1 毫秒) | 50.4 帧/秒(9 毫秒/8 毫秒) | 22 帧/秒(44 毫秒/1 毫秒) |
| Radeon 5600 M | 73.3 帧/秒 | 35.2 帧/秒(6 毫秒/16 毫秒) | 25.7 帧/秒(19 毫秒/13 毫秒) | |||
| Radeon 4800H | 11.7 帧率 | 7.5 帧/秒(35 毫秒/66 毫秒) | 5.2 帧/秒(109 毫秒/52 毫秒) |
- CS Static是我们帖子中的计算着色器光线追踪(总共 40M 个三角形)。
- CS Dynamic Fast是本文中的计算着色器光线追踪(总共 420 万个三角形和 290 万个顶点)。
- CS Dynamic Full与CS Dynamic Fast相同,但具有完整的 BLAS 重建而不是快速 BVH 更新。
- API Static、API Dynamic Fast和API Dynamic Full使用 API 提供的光线追踪。
- 计时显示 BLAS 更新/场景跟踪时间。
在这些测试中,新的 Arc 架构在线程差异较大的负载上展示了更好的计算性能。与计算着色器实现相比,硬件光线追踪速率非常高。根据结果推断,Arc 770M 的 RT 性能应该优于 AMD Radeon GPU 的 RT 性能。
让我们看看 BLAS 和 Scratch 缓冲区需要多少内存:
| 静态BLAS | 静电划痕 | 动态BLAS | 动态划痕 | |
|---|---|---|---|---|
| 英特尔Arc A370M | 66MB | 23MB | 642MB | 280MB |
| 苹果M1 | 82MB | 88MB | 355MB | 382MB |
| GeForce 2080 钛 | 33MB | 10MB | 255MB | 16MB |
| Radeon 6700 XT | 77MB | 105MB | 656MB | 887MB |


新款英特尔 GPU 的数据看起来很有希望。但 GravityMark 基准测试在 D3D12(光栅和 RT)API 上崩溃,而 Arc 应该在其中展示其潜力。但事实上,我们的结果比英特尔 Xe 一代还差,甚至比苹果 A15 还差。希望它能通过新的驱动程序更新得到改进,因为目前英特尔 Xe 比英特尔 Arc 更快。
Intel Arc和Intel Xe在计算性能上没有太大差异。因此驱动程序可能可以使用两个 GPU 进行渲染。就像模拟在不同 GPU 上工作的多个计算队列一样。如果这是真的,英特尔的驱动团队还有很多工作要做。
更新:具有 GPU 指定计数的 ExecuteIndirect() 会使 D3D12 驱动程序崩溃。CPU-GPU 同步解决方法(计数参数获取)允许在 D3D12 上运行 GravityMark。但不幸的是,这种解决方法并不能帮助 Vulkan 达到与 D3D12 一样快的速度。
更新 2:得益于英特尔开发者关系,简单的引擎优化(灵活的子组大小)可在 Vulkan 中的英特尔 Arc GPU 上提供超过 200% 的性能提升。